RL Weekly 36: AlphaZero with a Learned Model achieves SotA in Atari
Por um escritor misterioso
Last updated 28 dezembro 2024

In this issue, we look at MuZero, DeepMind’s new algorithm that learns a model and achieves AlphaZero performance in Chess, Shogi, and Go and achieves state-of-the-art performance on Atari. We also look at Safety Gym, OpenAI’s new environment suite for safe RL.

Denis Yarats on X: Impressive improvements in data-efficiency on Atari 100K, shattering our month old SOTA results from DrQ! Glad to see that some of our ideas ended up being useful in
Tags
RL Weekly 9: Sample-efficient Near-SOTA Model-based RL, Neural MMO, and Bottlenecks in Deep Q-Learning

Mastering Atari Games with Limited Data – arXiv Vanity

ICLR 2022

PDF) Alpha-T: Learning to Traverse over Graphs with An AlphaZero-inspired Self-Play Framework
Aman's AI Journal • Papers List

Memory-based Reinforcement Learning

PDF) OCAtari: Object-Centric Atari 2600 Reinforcement Learning Environments
Recomendado para você
-
 Only Alphazero Can Sacrifice like This !! Alphazero Vs Stockfish 15, Game 22, Stokfish28 dezembro 2024
Only Alphazero Can Sacrifice like This !! Alphazero Vs Stockfish 15, Game 22, Stokfish28 dezembro 2024 -
 AlphaZero on Carlsen-Caruana Games 1-828 dezembro 2024
AlphaZero on Carlsen-Caruana Games 1-828 dezembro 2024 -
 Alphazero :: Computer-bridge128 dezembro 2024
Alphazero :: Computer-bridge128 dezembro 2024 -
 A New Kind Of Chess! - AlphaZero vs. Stockfish, 201728 dezembro 2024
A New Kind Of Chess! - AlphaZero vs. Stockfish, 201728 dezembro 2024 -
How AlphaZero Completely CRUSHED Stockfish ( Part 4 ) #chess #gotha28 dezembro 2024
-
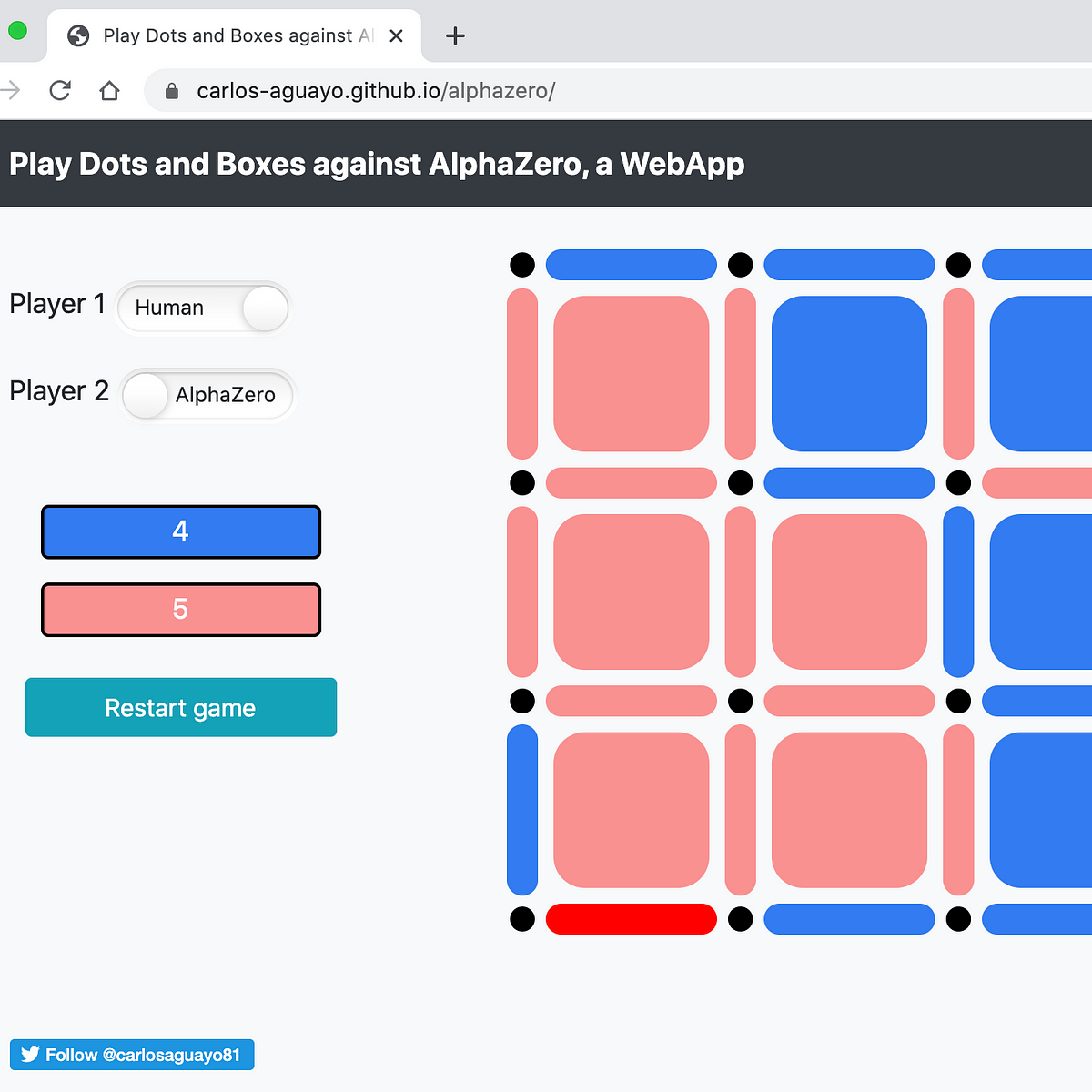 AlphaZero, a novel Reinforcement Learning Algorithm, in JavaScript28 dezembro 2024
AlphaZero, a novel Reinforcement Learning Algorithm, in JavaScript28 dezembro 2024 -
 How the Artificial Intelligence Program AlphaZero Mastered Its Games28 dezembro 2024
How the Artificial Intelligence Program AlphaZero Mastered Its Games28 dezembro 2024 -
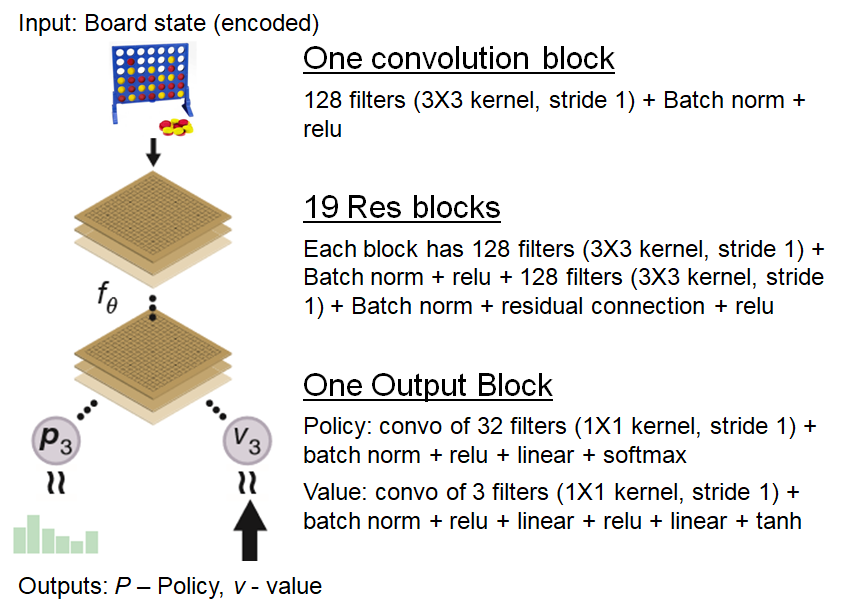 From-scratch implementation of AlphaZero for Connect4, by Wee Tee Soh28 dezembro 2024
From-scratch implementation of AlphaZero for Connect4, by Wee Tee Soh28 dezembro 2024 -
 AlphaZero – a generic game-beater28 dezembro 2024
AlphaZero – a generic game-beater28 dezembro 2024 -
 Machine Learning for Chess — AlphaZero vs Stockfish28 dezembro 2024
Machine Learning for Chess — AlphaZero vs Stockfish28 dezembro 2024

você pode gostar
-
 IDJ e FACV assinam protocolo de parceria institucional para dinamizar o Desporto Milita - Instituto do Desporto e da Juventude28 dezembro 2024
IDJ e FACV assinam protocolo de parceria institucional para dinamizar o Desporto Milita - Instituto do Desporto e da Juventude28 dezembro 2024 -
 A New International Coordinator of FCJ Companions in Mission - Fidèles Compagnes de Jésus28 dezembro 2024
A New International Coordinator of FCJ Companions in Mission - Fidèles Compagnes de Jésus28 dezembro 2024 -
 Argentina v Venezuela, Round of 1628 dezembro 2024
Argentina v Venezuela, Round of 1628 dezembro 2024 -
![Episode 12 - Rent-A-Girlfriend [2020-09-25] - Anime News Network](https://www.animenewsnetwork.com/thumbnails/crop1200x630gH4/cms/episode-review.2/164489/screenshot-10197-.png.jpg) Episode 12 - Rent-A-Girlfriend [2020-09-25] - Anime News Network28 dezembro 2024
Episode 12 - Rent-A-Girlfriend [2020-09-25] - Anime News Network28 dezembro 2024 -
 USED STREET SIGN SCHOOL CROSSING YELLOW/GREEN w/BLACK DETAILS28 dezembro 2024
USED STREET SIGN SCHOOL CROSSING YELLOW/GREEN w/BLACK DETAILS28 dezembro 2024 -
Baki Melhor Anime28 dezembro 2024
-
![Anime Mini Review]: Fate/Stay Night (+Unlimited Blade Works Movie](https://thegeekclinic.files.wordpress.com/2013/09/fate-stay-night-26.jpg) Anime Mini Review]: Fate/Stay Night (+Unlimited Blade Works Movie28 dezembro 2024
Anime Mini Review]: Fate/Stay Night (+Unlimited Blade Works Movie28 dezembro 2024 -
 Shadow Run 2 It's time : r/xboxone28 dezembro 2024
Shadow Run 2 It's time : r/xboxone28 dezembro 2024 -
 20th Century Fox Home Entertainment Logo (1994-2010) (FSP Style28 dezembro 2024
20th Century Fox Home Entertainment Logo (1994-2010) (FSP Style28 dezembro 2024 -
 Segurança de Nova Iguaçu ganha reforço com policiais motorizados28 dezembro 2024
Segurança de Nova Iguaçu ganha reforço com policiais motorizados28 dezembro 2024
